













EMO(Emote Portrait Alive)是什么:
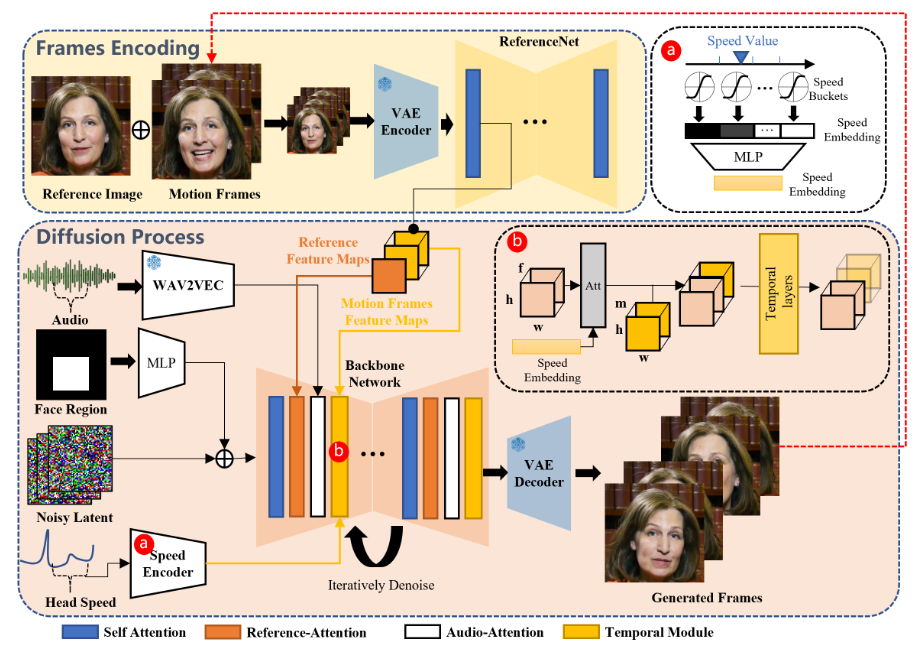
EMO是一个由阿里巴巴集团智能计算研究院研发的音频驱动的AI肖像视频生成系统。该系统能够根据输入的单一参考图像和语音音频生成具有表现力的面部表情和各种头部姿势的视频。它能捕捉人类表情的细微差别和个体面部风格的多样性,生成高度逼真和富有表现力的动画。
主要特点:
- 音频驱动的视频生成:支持从音频(如说话或唱歌)直接生成视频。
- 高表现力和逼真度:捕捉人类面部表情的细微差别,包括微表情和头部运动。
- 无缝帧过渡:确保视频帧间过渡自然,避免面部扭曲或抖动。
- 身份保持:通过FrameEncoding模块保持角色身份的一致性。
- 稳定的控制机制:使用速度控制器和面部区域控制器增强生成稳定性。
- 灵活的视频时长:根据输入音频长度生成任意时长的视频。
- 跨语言和跨风格:支持多种语言和风格,包括中文、英文、现实主义、动漫和3D风格。
主要功能:
- 音频驱动的视频生成:输入音频和参考图像,生成同步的视频。
- 高表现力和逼真度:生成捕捉细微表情和头部运动的视频。
- 无缝帧过渡:提供流畅的视频观看体验。
- 身份保持:确保视频中角色外观与输入参考图像一致。
- 稳定的控制机制:通过控制机制保证视频生成过程的稳定性。
使用示例:
用户可以上传一张个人照片和一段音频,EMO将生成一个视频,其中用户的肖像将根据音频内容展示相应的面部表情和头部动作。这可以用于社交媒体分享、虚拟主播、在线教育等多种场景。
总结:
EMO通过其先进的音频驱动视频生成技术,为用户带来了一种创新的方式来创造个性化和富有表现力的视频内容。它不仅能够生成逼真的面部表情,还能根据音频内容自然地驱动头部动作,为用户提供了一种强大的工具来表达和分享他们的内容。随着未来模型和源码的开源,我们期待EMO能够在更广泛的应用场景中发挥作用。更多关于EMO的信息可以在其官方项目主页和arXiv研究论文中找到。
相关导航
















Copyright©2023-2025 AIGC工具导航 津ICP备2022006237号-2 津公网安备12011002023007号 12377违法和不良信息举报中心 互联网违法和不良信息举报渠道
津公网安备12011002023007号 12377违法和不良信息举报中心 互联网违法和不良信息举报渠道