













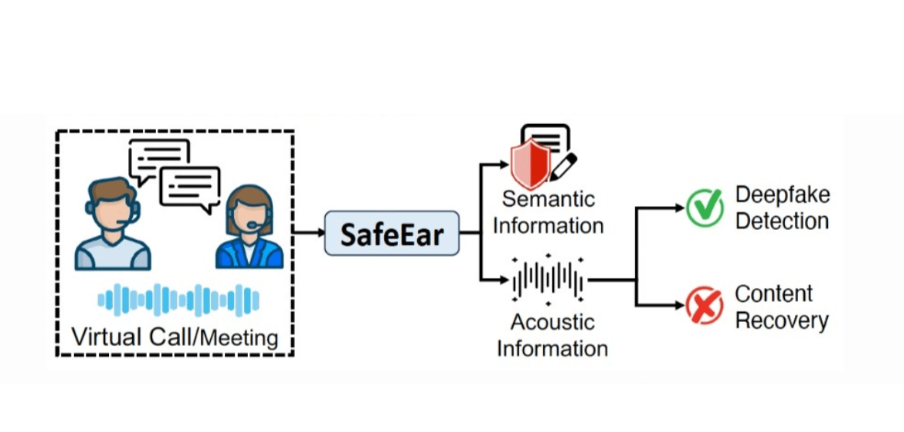
SafeEar是什么:
SafeEar是由浙江大学和清华大学联合开发的AI音频伪造检测框架,旨在保护用户隐私的同时检测音频伪造。它采用基于神经音频编解码器的解耦模型,分离语音的声学信息和语义信息,仅用声学信息进行检测,有效防止隐私泄露。SafeEar在多个基准数据集上表现优异,等错误率(EER)低至2.02%,能抵御内容恢复攻击,并提供了多语言支持。
主要特点:
- 隐私保护:通过分离语义和声学信息,保护语音内容的隐私。
- 多语言支持:能处理和检测多种语言的音频数据。
- 高效的伪造检测:在公开基准数据集上EER低至2.02%。
- 抗内容恢复技术:即使在对抗性攻击下也能保持高检测准确率。
- 真实环境增强:模拟真实环境中的音频信道多样性,增强模型泛化能力。
- 开源资源:提供论文、代码和数据集的开放访问。
主要功能:
- 深度伪造检测:检测音频是否经过伪造处理。
- 隐私保护:在检测过程中保护语音内容的隐私。
- 多语言处理:支持多种语言的音频数据检测。
- 数据集构建:构建了包含150万条多语种音频数据的CVoiceFake数据集。
使用示例:
- 社交媒体监控:检测社交媒体上的音频内容是否为伪造。
- 法律证据验证:在法律程序中验证音频证据的真实性。
- 金融交易安全:提高金融机构中语音识别系统的安全性。
- 国家安全:帮助政府和安全机构识别潜在的威胁和虚假信息。
总结:
SafeEar是一个创新的音频伪造检测工具,它通过先进的AI技术保护用户的语音隐私,同时提供高效的伪造音频检测能力。它的多语言支持和抗攻击能力使其在多个领域都有广泛的应用前景。
相关导航

















Copyright©2023-2025 AIGC工具导航 津ICP备2022006237号-2 津公网安备12011002023007号 12377违法和不良信息举报中心 互联网违法和不良信息举报渠道
津公网安备12011002023007号 12377违法和不良信息举报中心 互联网违法和不良信息举报渠道