













Draw an Audio是什么:
Draw an Audio是由中国科学院自动化研究所和美团点评的研究人员共同开发的一个视频生成音频系统。该系统能够根据视频内容自动生成匹配的声音效果,类似于电影制作中的Foley艺术。
主要特点:
- 内容一致性:生成与视频场景语义相匹配的声音。
- 时间一致性:音频与视频中的动作精确同步。
- 响度一致性:根据视频中的动作强度调整声音的响度。
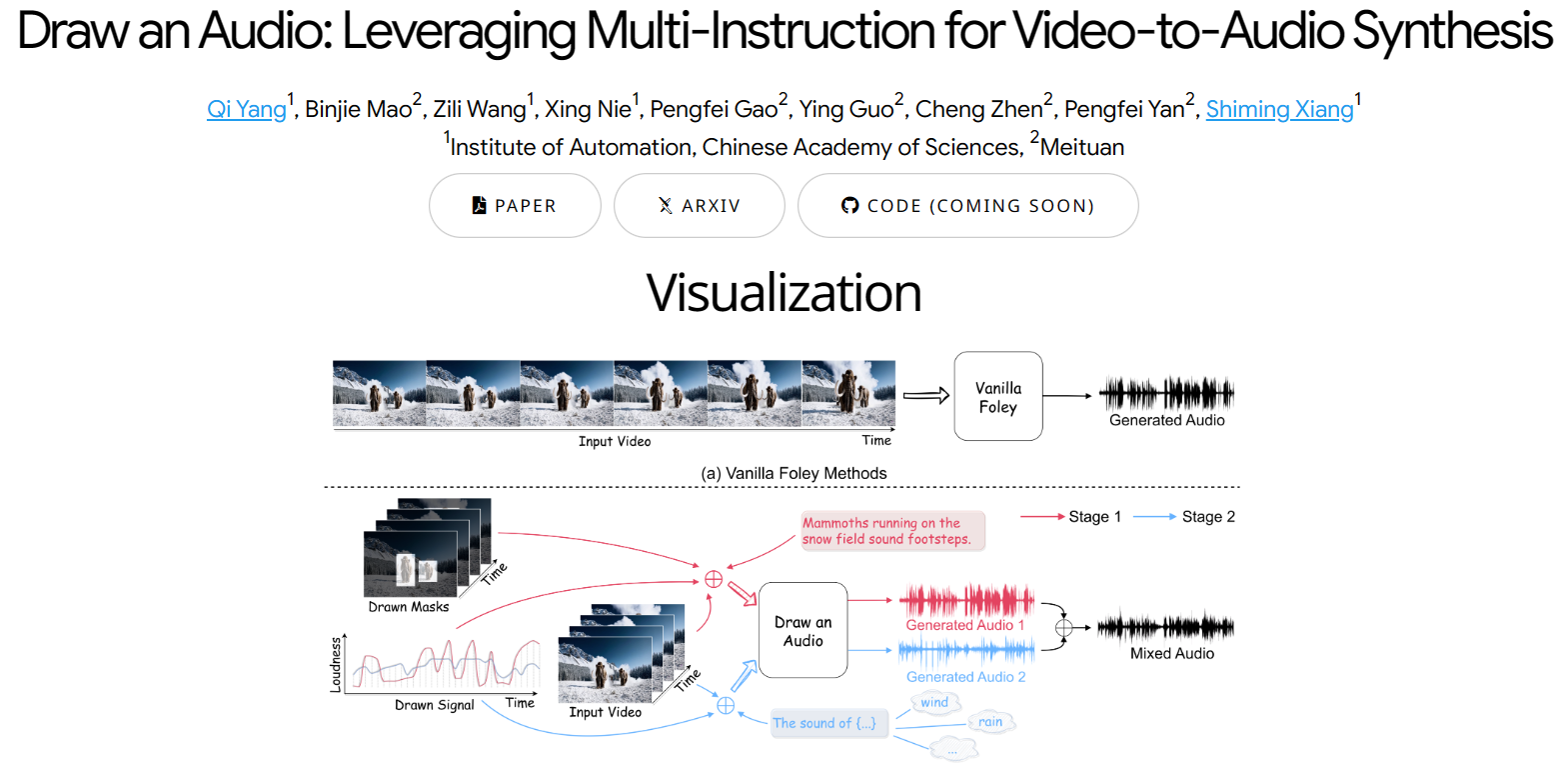
- 多指令输入:支持多种输入指令,如文本、视频遮罩和响度信号。
主要功能:
- 内容一致性:系统分析视频内容,生成与视频场景语义相匹配的声音。
- 时间一致性:生成的音频与视频中的动作精确同步。
- 响度一致性:系统根据视频中的动作强度调整声音的响度。
- 多指令输入:系统支持多种输入指令,使音频生成更加灵活和可控。
- 高质量的同步音频:利用多指令生成与视频内容自然同步的高质量音频。
技术原理:
- 潜在扩散模型(LDM):作为基础模型,负责处理音频数据的基本生成和处理。
- 文本条件模型:处理文本指令,提高内容的语义一致性。
- 掩码注意力模块(MAM):通过视频遮罩来关注视频的重点区域,增强视频内容与生成音频之间的一致性。
- 时间-响度模块(TLM):处理信号指令,确保生成的声音在时间和响度上与视频同步。
应用场景:
- 电影和视频制作:自动为无声视频添加匹配的音效,提高制作效率。
- 游戏开发:为游戏中的动画和场景生成逼真的声音效果。
- 虚拟现实(VR)和增强现实(AR):在虚拟环境中生成与场景相匹配的声音,提升用户体验。
- 教育和培训:为教育视频自动生成解释性的声音,帮助学生更好地理解。
- 动画制作:自动生成动画角色的对话和环境音效,使动画制作更加高效。
- 广告制作:为广告视频生成吸引人的音频效果,增强广告吸引力。
总结:
Draw an Audio是一个创新的视频生成音频系统,它通过先进的AI技术,能够自动分析视频内容并生成与之匹配的声音效果。该系统不仅提高了声音设计过程的效率,还为各种媒体制作领域带来了新的可能性。
相关导航
















Copyright©2023-2025 AIGC工具导航 津ICP备2022006237号-2 津公网安备12011002023007号 12377违法和不良信息举报中心 互联网违法和不良信息举报渠道
津公网安备12011002023007号 12377违法和不良信息举报中心 互联网违法和不良信息举报渠道