













K2是什么?
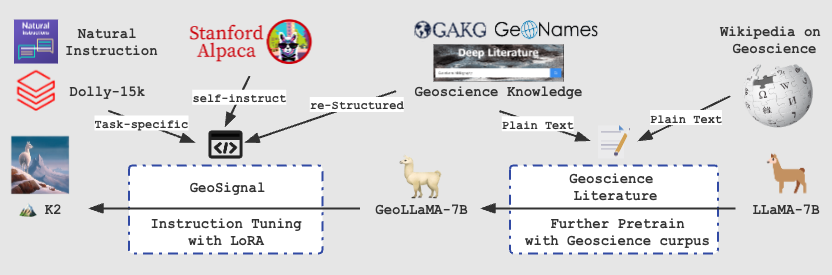
K2是上海交通大学专门为地球科学领域设计的开源大语言模型。它通过进一步预训练和微调,增强了对地球科学知识的理解和应用能力,使其在处理地球科学相关任务时表现更为出色。
主要特点:
- 领域专精:K2专注于地球科学领域,对相关文献和数据有深入的学习和理解。
- 数据预处理:通过收集和清理地球科学文献,包括开放获取论文和维基百科页面,为模型提供高质量的训练数据。
- 预训练基础:基于LLaMA模型进行进一步的预训练,以增强其语言理解能力。
- 微调优化:使用GeoSignal等知识密集型指令调整数据对模型进行微调,以提高其在特定任务上的表现。
主要功能:
- 文献理解:能够理解和分析地球科学领域的文献资料。
- 知识应用:将学习到的知识应用于解决地球科学问题。
- 基准测试:通过GeoBenchmark等基准测试评估模型性能。
- 代码和数据共享:提供代码和数据集,以支持研究和进一步的开发。
使用示例:
假设你是一名地球科学研究者,你可以使用K2来:
- 分析大量的地球科学文献,提取关键信息和数据。
- 解决复杂的地球科学问题,如地质学、地理学和环境科学中的特定问题。
- 利用K2进行基准测试,评估你的研究成果与现有模型的对比。
- 访问K2的代码和数据集,进行自定义的模型训练和实验。
总结:
K2是一个为地球科学领域量身定制的开源大语言模型,它通过专业的预训练和微调过程,展现出在地球科学知识理解和应用方面的优势。K2的开源特性也促进了学术界和工业界的进一步研究和应用开发,为地球科学知识的传播和利用提供了有力的工具。
相关导航















Copyright©2023-2025 AIGC工具导航 津ICP备2022006237号-2 津公网安备12011002023007号 12377违法和不良信息举报中心 互联网违法和不良信息举报渠道
津公网安备12011002023007号 12377违法和不良信息举报中心 互联网违法和不良信息举报渠道