CosyVoice2.0 – 阿里开源的语音生成大模型

一、工具概述
CosyVoice2.0是阿里巴巴通义实验室推出的语音生成大模型升级版。它是一款基于先进的监督离散语音标记技术的多语言语音合成模型,旨在通过有限标量量化技术和块感知因果流匹配模型,提升语音合成的质量。
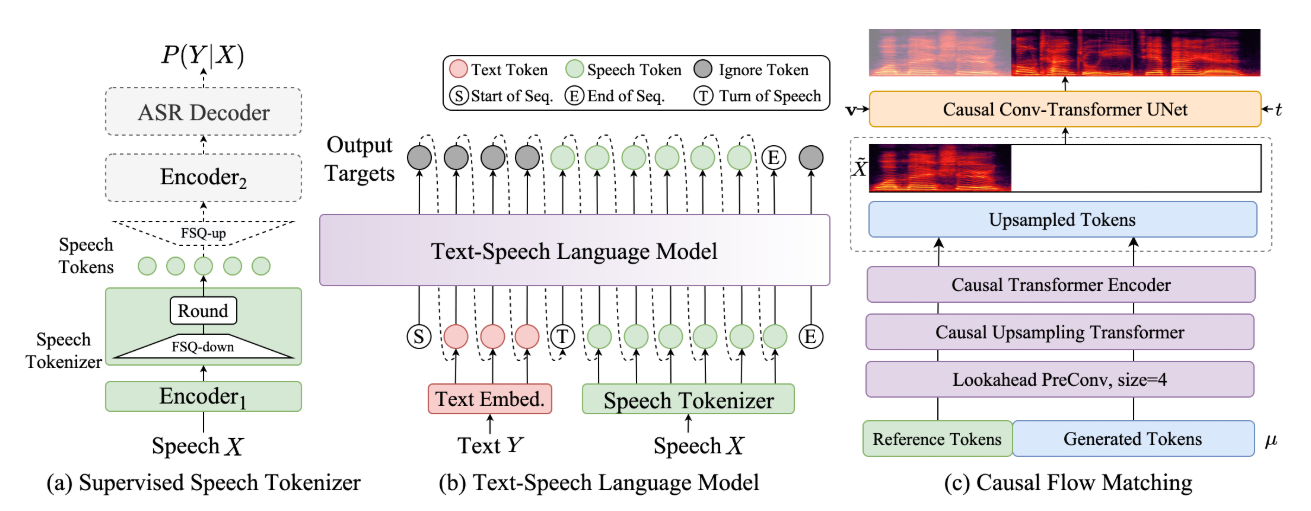
这个工具在继承前代产品优势的基础上进行了深度优化,简化了文本 – 语音语言模型架构,支持多样的合成场景,并在发音准确性、音色一致性、韵律和音质上都有显著提升。CosyVoice2.0采用了全尺度量化和离线流式一体化建模,支持多语言和指令可控的音频生成,适合实时语音合成场景。
二、功能特点
(一)超低延迟的流式语音合成
CosyVoice2.0支持双向流式语音合成,首包合成延迟仅150ms,这一特性极大地提升了互动效率,使其非常适合实时应用场景,例如智能客服和虚拟助手等需要即时反馈的应用场景。
(二)高准确度的发音
与前版本相比,CosyVoice2.0的发音错误率显著下降,范围在30% – 50%之间,尤其在处理绕口令、多音字、生僻字等高难度场景时表现出优异的性能,并且在Seed – TTS难度测试集上创下了最低字错误率记录。
(三)音色一致性
在零样本和跨语言语音合成中,CosyVoice2.0能够保持音色高度一致性,提升了合成语音的自然度。这有助于在各种需求下生成稳定、自然的语音,例如跨语言的语音合成任务或者在零样本基础上进行语音克隆。
(四)多语言支持
经过大规模多语言数据集的训练,CosyVoice2.0实现了多语言和跨语言的语音合成能力。除了已有的多种语言支持,新版本还新增了丰富的方言支持,包括粤语、四川话、郑州话、天津话和长沙话等,满足不同地域和用户群体的多样化需求。
(五)丰富的情感和风格控制
它提供更细粒度的情感和语气控制选项,可以生成如愉悦、悲伤、激动等不同情感的语音,模仿各种说话风格,比如能够像机器人、动画角色等特定风格的语言表达,为语音合成带来更多创意和个性化可能,提升用户的交互体验和音频内容的丰富性。
(六)自然的语音体验
在韵律、音质和情感对齐方面,CosyVoice2.0有显著增强。其MOS (Mean Opinion Score)评测分数从5.4提高到5.53,接近商业化语音合成大模型的水平,使得生成的语音更加自然、流畅,符合人们对高质量语音的需求。
三、使用方法
(一)环境配置
首先需要创建Conda环境并安装相关依赖。具体的操作细节虽然没有详细给出,但这是使用CosyVoice2.0的前置步骤,可能涉及到特定的软件包、插件等的安装和设置,以确保后续功能可以正常运行。
(二)模型下载
完成环境配置后,需要进行模型下载。这一步是获取CosyVoice2.0工具的模型数据,以便用于语音合成任务的计算基础,但文档未提及具体的下载方式和源地址,可能在官方文档或者指定的开源平台获取相关内容。
(三)基本使用
- 文本输入:按照任务要求在相应位置输入需要合成语音的文本内容。
- 推理模式选择:它具有多种推理模式可供选择,例如基础音色快速生成模式下用户可以在内置的多种音色(如中文、粤语、日语等)中选择;如果要进行音色克隆,可选择“3秒极速复刻”模式,还可选择“跨语种复刻”模式用于跨语言语音合成;还有自然语言控制等其他模式,可以根据不同的需求实现多样化的语音合成。
- 附加设定(可选):用户能够进行一些附加操作,例如在某些模式下,可能需要上传目标声音文件或者使用“录音”按钮录制素材;对于有“输入Prompt文本”框的情况,要准确输入对应素材文件中的文字内容;另外,还可以调整像语速、随机种子等选项来尝试获得不同的语音效果。
- 音频生成与听取:全部设定完成后,点击生成音频按钮就可以等待语音生成,之后在页面底部的输出音频界面可以播放和下载合成后的语音。
四、应用场景
(一)智能客服
在智能客服领域,CosyVoice2.0的超低延迟和高准确性发挥了关键作用。由于首包合成延迟低至150毫秒,当客户咨询问题时,它能够迅速启动语音合成,快速准确地回答客户的问题,避免了客户长时间等待。高准确度的发音也确保了交流的顺畅,极大地提高了客户服务的效率和质量。同时,其自然的语音体验能够让客户感受到更加人性化的服务,提升客户的满意度和信任度,为企业塑造良好的品牌形象,提高企业的竞争力。
(二)虚拟助手
对于虚拟助手应用,CosyVoice2.0的个性化语音功能是一大亮点。用户可以根据自己的喜好,利用其提供的对语音情感、语气进行精细调整的功能,使虚拟助手的语音更符合自己的使用习惯和情感需求。例如,在早晨,用户可以选择一个充满活力、欢快的语音风格来获取天气、新闻等信息;而在晚上则切换到柔和、舒缓的语音模式放松身心。丰富的方言支持还能够让虚拟助手更好地与不同地区用户进行沟通,增加用户与虚拟助手交互的亲切感和自然度,成为用户生活中的贴心伙伴。
(三)教育与培训
在教育与培训场景中,CosyVoice2.0为学习者提供了强大的辅助工具。精准的发音有助于学生更好地学习外语发音,通过模仿标准的语音示范来纠正自己的发音错误,从而提高语言学习的效果。对于阅读障碍者或者有有声读物需求的人群,它能够将文字内容高质量地转化为语音,为他们提供更便捷、高效的学习和阅读体验,促进知识的传播和获取。例如在语言学习课程中,可以直接利用CosyVoice2.0生成不同语言的语音,帮助学生练习听说能力;或者在制作教学课件时,嵌入其生成的语音内容,丰富教学资源。
(四)娱乐内容创作
在影视、游戏等娱乐产业中,CosyVoice2.0的可控音频生成能力为创作者们带来了无限创意空间。它可以生成各种逼真的角色声音,涵盖从英勇的战士到可爱的卡通形象,从神秘的魔法师到威严的帝王等各类角色,满足不同角色的语音需求,为作品增添丰富的听觉元素和魅力。独特的语音风格模仿功能可用于创造具有特殊效果的音频片段,像模仿经典动画角色的声音进行二次创作,或者为游戏中的特殊场景打造独特音效,大大提升娱乐内容的趣味性和吸引力。
(五)智能家居
在智能家居环境下,CosyVoice2.0使用户能够通过简单的语音指令轻松操控家电、灯光、窗帘等设备,实现便捷的语音控制。例如,忙碌时,用户一句话就能让扫地机器人开始工作;睡前通过语音关闭灯光、调整空调温度等。这种智能化操作无需手动进行,真正提高了生活的便利性和舒适度,让智能家居系统更加智能、高效、易用。
五、与同类工具对比
(一)语音合成技术架构
- CosyVoice2.0:它基于预训练的文本基座大模型(如Qwen2.5 – 0.5B),采用全新的设计替换了原有的TextEncoder结构,同时引入FSQSpeechTokenizer替代传统向量量化方案,通过训练更大码本(6561)实现100%激活率,从而提升发音准确性。这种特定的技术架构能够让其在语音合成时能充分利用预训练模型在语义理解等方面的优势,进行更精准、高效的文本语义建模,简化的架构也有助于更好地适应多种场景提出的需求。
- 其他同类工具:很多同类工具可能采用不同的架构基础,有的可能仍然基于传统的TextEncoder + RandomTransformer结构或者其他非基于预训练大模型的方式构建。这些架构在文本处理和语义理解能力方面可能相对较弱,导致发音准确性、语音自然度等方面存在差异。例如在处理复杂文本或者生僻词汇时,表现不如CosyVoice2.0,语音可能会出现不自然或者发音错误的情况。
(二)语音合成性能表现
- CosyVoice2.0:在多个性能指标上展现出优势。其超低的首包合成延迟仅为150ms,实现了双向流式语音合成,在实时应用场景中表现优异;发音准确性显著提升,错误率下降30% – 50%,尤其在处理绕口令、多音字等复杂情况下表现出色;在音色一致性方面,零样本和跨语言语音合成时能保持高度一致;MOS评测分数从5.4提升至5.53,在音质、韵律和情感匹配上接近商业化大规模语音合成模型,呈现出非常高的语音合成质量。
- 其他同类工具:部分同类工具可能存在在低延迟和高性能两者之间难以平衡的问题,要么延迟较高,影响实时交互体验,要么为了追求低延迟而在发音准确性或者其他语音特性方面做出妥协。在音色一致性上,一些工具可能在跨语言或者零样本语音合成时出现音色波动较大的情况,导致生成的语音听起来不够自然和连贯。
(三)语音功能丰富度
- CosyVoice2.0:支持丰富的功能。它不仅有多语言和多方言支持(新增多种方言如粤语、四川话等),还具备创新的角色扮演功能,能模仿机器人、动画角色等特定说话风格,同时提供更细粒度的情感和语气控制选项,用户可以生成具有不同情感(愉悦、悲伤等)的语音。这些功能为用户提供了非常多样化的语音创作空间,可以满足不同应用场景从语音助手到娱乐创作等多方面的需求。
- 其他同类工具:相对而言,部分同类工具功能较为单一,可能仅支持基本的语音合成功能,语言种类支持有限,缺乏对不同情感、风格等方面细致的控制能力。在方言支持方面也可能比较薄弱,不能很好地满足特定地域或者用户对特殊风格语音的需求。













Copyright©2023-2025 AIGC工具导航 津ICP备2022006237号-2 津公网安备12011002023007号 12377违法和不良信息举报中心 互联网违法和不良信息举报渠道
津公网安备12011002023007号 12377违法和不良信息举报中心 互联网违法和不良信息举报渠道