说在前面的话
今天阿里的通义模型低调公开,首先这是一件非常值得我们开心的一件事情。我也非常荣幸有机会拿到了体验的入场券,看来我知乎指日可待!
我进行了简单进行了两方面的测试,对模型的能否持续对话,和模型对于一些逻辑问题的理解能力进行了评估,阿里的模型大概可能只有GPT3的水平,我感觉没有那种很惊喜的感觉,其实很多地方都是再试图去补充一个回答,使得回答看起来像一个人类所说的话,但是逻辑性以及回答的正确性而言确实是不能够达到我的及格线要求。
连贯性测试


在如何学习ai4sci这个问题上,进行了大概3句话描述就开始出现了逻辑断层,不过按照上面的解释而言,它确实不理解什么是ai4sci,但是逻辑的连贯是具备的。
我们来测试一下一个经典的逻辑问题


文心一言的情况


ChatGPT3.5的理解
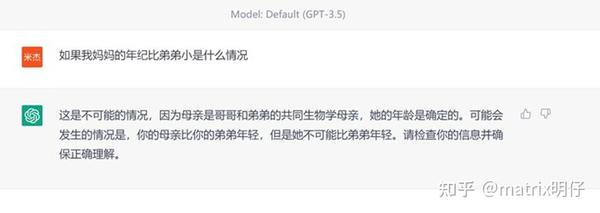
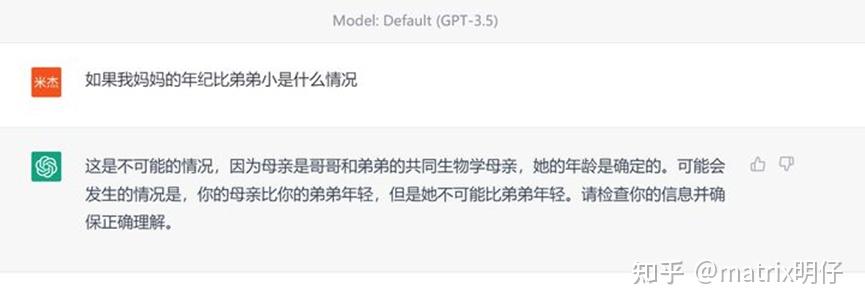
但是我觉得有很多值得肯定的地方是,这个模型有再试图去做出一些不一样的尝试,它试图去将通用模型变得更加专家化。其实目前我们可以看到,国内的模型,文心一言,通义千问都做出了自己的答案,当然我们也看到了距离。我们会发现通义和文心都无法合理的做出逻辑上的判断,比较机械的顺从使用者的问题,从这点看,确实我觉得国内的模型对于“有害性”的研究其实还不足够,倒是还停留在拟合精细数据的层面上。但是相较于文心而言,通义会更加鼓励去回答,即使答案越说越错,但是我觉得这是一个语言模型好的开始。虽然短的模型看上去暴露的问题会比较少,但是者,准确率会更好,但是这并不是一个我们所追求的发展思路。
我最直观的使用体验上是觉得,国内的模型在语料方面依然是不足的,这或许有两个原因
1、无法收集到庞大的预料数据集,或者标注出一个大的语料数据
2、训练的成本受限,无法负担过大规模的模型训练。
我觉得这两点原因可能是目前我们的模型发展依旧无法超越open.ai的比较大的原因。确实缺这样的资金去负担一个通用大模型。
但是目前chatgpt的问题也比较明显,就是专家特性不够强。所以其实国内的大模型可以找个专属的小赛道卷,规避正面战场,打打游击也是非常具有收益的方式。
对于这个问题,阿里给出了自己的答案,因为有类似于阿里系的淘宝、钉钉一样的系列软件的积累,所以会比较顺其自然的推出一些协助高效办公的插件,也帮助2B的销路会更加的好。就拿本人来举例子,我对于商品描述,和SWOT这些商业分析的工具是非常感兴趣的
我来尝试一下康师傅红烧牛肉面


文心一言


ChatGPT3.5


其实就红烧牛肉面商品描述而言,通义的真实程度我觉得是我可以认可的,至少洋葱和牛肉块我是没有办法认可的。我觉得在商品环节上整体的真实性是完全可以可以到80分的,但是我们其实也肉眼可见,在文本的可读性上还是有不小的瑕疵,这点也是后续会不断通过语料扩充进行优化的。
坦白局


我们尝试让通义说一说自己和chatgpt的区别,但是这个问题似乎是被调教过,但是似乎紧张过头了,重复生产了两遍缺点,有点口吃!逻辑也不太对,也出现了很多不可读的情况,看来要回答这样的具有总结性的问题,通义似乎还有很长的路要走。
目前的GPT/AIGC
其实对于open.ai开发出chatgpt后,大家都纷纷开始加入研究看来,AGI毫无疑问已经变成了业界新宠儿,在这个过程中我看见很多单位all in 大模型,但是都好像没有做出什么亮眼的成绩出来。百度做了第一个开放的勇士,阿里就是第二个,后续还有华为的盘古,等等等等。差距是有的,但是好在大模型从来不是一个闭门造车的技术发展路线,开放后的模型,拥有更多的批评,但是也能积累更多的语料语义的反馈。目前的发展上来看,及时的开放可以很好的解决第一点的问题,优质,量大的数据集能够很快的补充,但是目前而言,在数据的影响逐步缩小,数据总量对齐的情况下,现阶段国内的模型会爆出第二次雷,会是在结构上的差距。不过得益于多年销售和运营的经验,我们也尝试避开主流赛道,尝试开发有意思的插件,保本方面,也有很多不同的方法,所以按照我目前看来,国内的大模型整体趋势还是稳一手的发展。
通义的缺点
其实通义的缺点还是真的比较多的,首先就是一本正经的胡说八道,文本语义正确性不高,但是结构是有的。如果是在不具备先验认知的情况下是有可能产生生产误导的。就比如把MMYOLO认为是自己体系下的算法库,和GPT3.5当时测试的结果一致。不过这样的问题当然在gpt上也依旧存在,也正像通义自己所说这是由专业知识覆盖不到位导致的。


展望未来
“卖chatgpt号的都买房了”这句话我已经在很多群里都听见了,也传开了,目前gpt爆发的巨大市场,让我还有很多朋友都十分震撼。作为一个AI模型,通义千问有很多优秀的性能,但是它仍然有一些局限性和缺陷,例如数据质量、数据偏差、模型复杂度和算法限制等。因此,未来的努力方向之一可能是通过改进数据质量和数据预处理、优化模型复杂度和算法、加入更多的先进技术等方式,进一步提升通义千问的性能和应用价值。
相关文章









Copyright©2023-2025 AIGC工具导航 津ICP备2022006237号-2 津公网安备12011002023007号 12377违法和不良信息举报中心 互联网违法和不良信息举报渠道
津公网安备12011002023007号 12377违法和不良信息举报中心 互联网违法和不良信息举报渠道