“如果一个年轻人了解如何训练5层神经网络,他可以要求5位数的年薪。如果这个年轻人懂得如何训练50层神经网络,那么他可以要求7位数的年薪。”——Deep learning
通用人工智能是什么,或者说它需要具有哪些能力?
1.逻辑推理能力。
2.学习迁移能力。
然而现在的人工智能,有多少人工就有多少智能。
在我国数据标注员的岗位,根据项目标注和要求,对文本、音频、图片等数据进行归类、整理、编辑、纠错和批注,工资通常计件付费,属于互联网时代的流水线工人。
另外,据亚马逊称,土耳其机器人提供的是“一个需要人类智慧的工作市场”。工人是指那些仅收取少量费用(例如,标注图像中的物体,每张照片的报酬是10美分)就愿意将其智慧用于完成请求者所要求的任务的人。
当前人工智能不仅依赖人力标注的大数据,还需要算法工程师编写程序,AI仍未产生理解事物本质的抽象思维能力。
人脑的数据存储能力远远低于AI,为何能让我们处理许多复杂的事物呢?
《表象与本质:类比》的作者侯世达认为,如若没有概念,就没有思维;而没有类比,概念就无从谈起,人类大脑中的每个概念都源于多年来在不知不觉间形成的一长串类比。人脑每时每刻都在用类比的能力处理问题。
《AI3.0》作者梅拉妮·米歇尔提出,理解任何情况,本质是一种能够预测接下来可能会发生什么的能力。
而由神经网络结构启发诞生的深度学习,更多的是归纳能力强大,因为喂了足够多的数据,力大砖飞,在特定领域发挥出色,但本身并不具备类比和预测的思维。
我们距离通用人工智能还有多远?
目前最热门语言模型的ChatGPT,它在搜集信息、归纳整理资料方面非常强大。最让我惊讶的是它的理解能力,它可能胡编乱造,但一定是按照你提出的问题胡编乱造,而不是鸡同鸭讲。它字面意思的理解能力已经远超过去的人工智能,你甚至可以和它玩文字版《群星》。
但它仍不具备演绎推理的能力。这点和人脑的差距太大了。人脑处理信息是自上而下和自下而上两个过程同时进行。以你画我猜为例,画的内容进入猜测者眼中,这是自下而上的,猜测者专注地盯着画面内容思考,甚至会忽略其他一切事物,这是自上而下的。“脑部”也是如此。但
对于一项复杂的技术项目,完成其前90%的工作往往只需要花费10%的时间,而完成最后10%则需要花费90%的时间。个人认为通用人工智能正在形成类似人类直觉的能力,大概发展进程位于前90%的位置。
最后闲扯,通用人工智能会产生自我意识吗?
我想,逻辑推理能力和学习迁移能力会赋予AI理解能力,而理解即模拟。
如果我们对概念和情境的理解是通过构建心智模型进行模拟来实现的,那么,也许意识以及我们对自我的全部概念,都来自我们构建并模拟自己的心智模型的能力。
如果这个理论正确,那么通用人工智能将会诞生自我意识。至于是铁心灭绝者、还是失控机仆,谁也不知道,智械危机也不是没有可能。


二、《AI3.0》笔记:人工智能的发展情况的梳理
1、符号人工智能,力图用数学逻辑解决通用问题。
由通用问题求解器所阐释的这类符号人工智能,在人工智能领域发展的最初30年里占据了主导地位,其中以专家系统最为著名。
2、感知机,依托DNN的亚符号人工智能
感知机是人工智能的一个重要里程碑,同时也催生了现代人工智能最成功的工具——DNN。
感知机是一个根据加权输入的总和是否满足阈值来做出是或否(输出1或0)的决策的简易程序。
它的权重和阈值不代表特定的概念,这些数字也很难被转换成人类可以理解的规则。
这一情况在当下具有上百万个权重的神经网络中变得更加复杂。
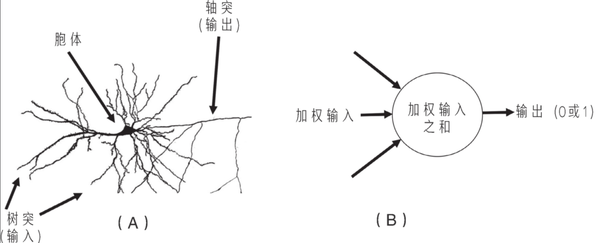
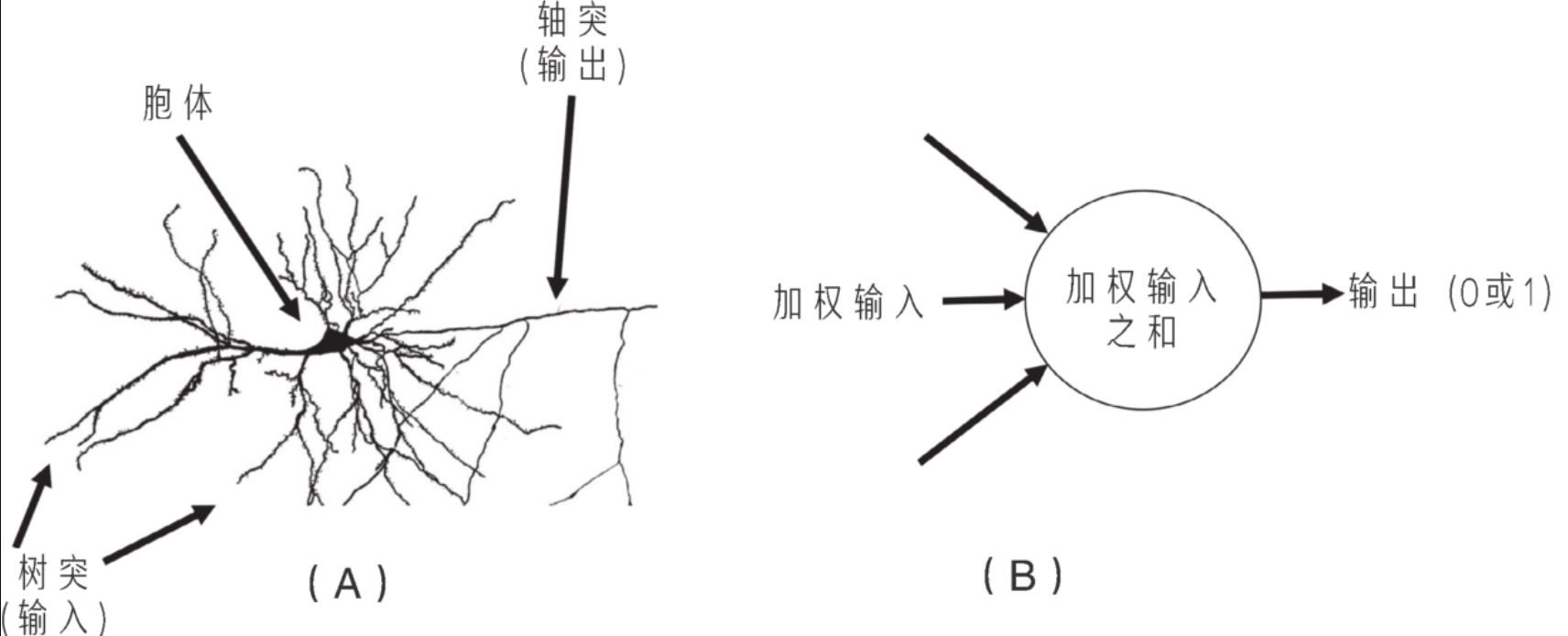
感知学习算法,无法重现人脑的涌现机制
涌现:由简单个体组成的复杂系统,去中心化,统一而又复杂的行为从其中涌现出来。比如蚁群的觅食合作行为,大脑神经元活动涌现的智慧。
我们发现神经刺激可以说是亚符号化的,但大脑已经创造了符号。
如果一个感知机通过添加一个额外的模拟神经元“层”来增强能力,那么原则上,感知机能够解决的问题类型就广泛得多,带有这样一个附加层的感知机叫作多层神经网络。多层神经网络构成了许多现代人工智能技术的基础。
3、多层神经网络
网络是以多种方式相互连接的一组元素的集合。
想象一下你的大脑结构,其中有一些神经元直接控制“输出”,如肌肉运动,但大部分神经元只与其他神经元互相传递信息,这些神经元被称为大脑的隐藏神经元。
原则上,多层神经网络可以有多层隐藏单元,具有多于一层隐藏单元的网络被称为“深度网络”(deep networks)。网络的深度就是其隐藏层的数量。
通常情况下我们很难提前知道,对于一个给定的任务,一个神经网络到底需要多少层隐藏单元,以及一个隐藏层中应该包含多少个隐藏单元才会表现更好,大多数神经网络研究人员采用试错的方式来寻找最佳设置。


4、ConvNets
研究人员发现,最成功的DNN是那些模仿了大脑的视觉系统结构的网络。ConvNets是当今计算机视觉领域正在进行的深度学习革命的驱动力,当然在其他领域也是如此。
当人的眼睛聚焦于一个场景时,眼睛接收到的是由场景中的物体发出或其表面反射的不同波长的光,这些光线激活了视网膜上的细胞,本质上说是激活了眼睛后面的神经元网格。这些神经元通过位于眼睛后面的纤长的视觉神经来交流彼此的激活信息并将其传入大脑,最终激活位于大脑后部视皮层的神经元(见图)。视皮层大致是由一系列按层排列的神经元组成,就像婚礼蛋糕那样一层一层堆在一起,每一层的神经元都将其激活信息传递给下一层的神经元。
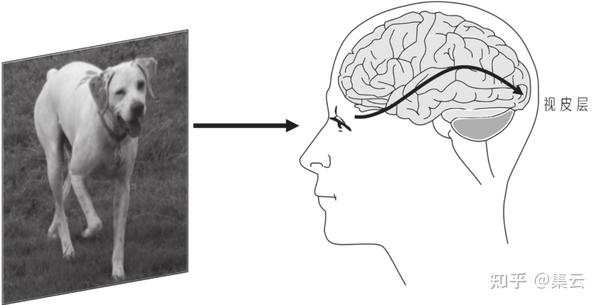
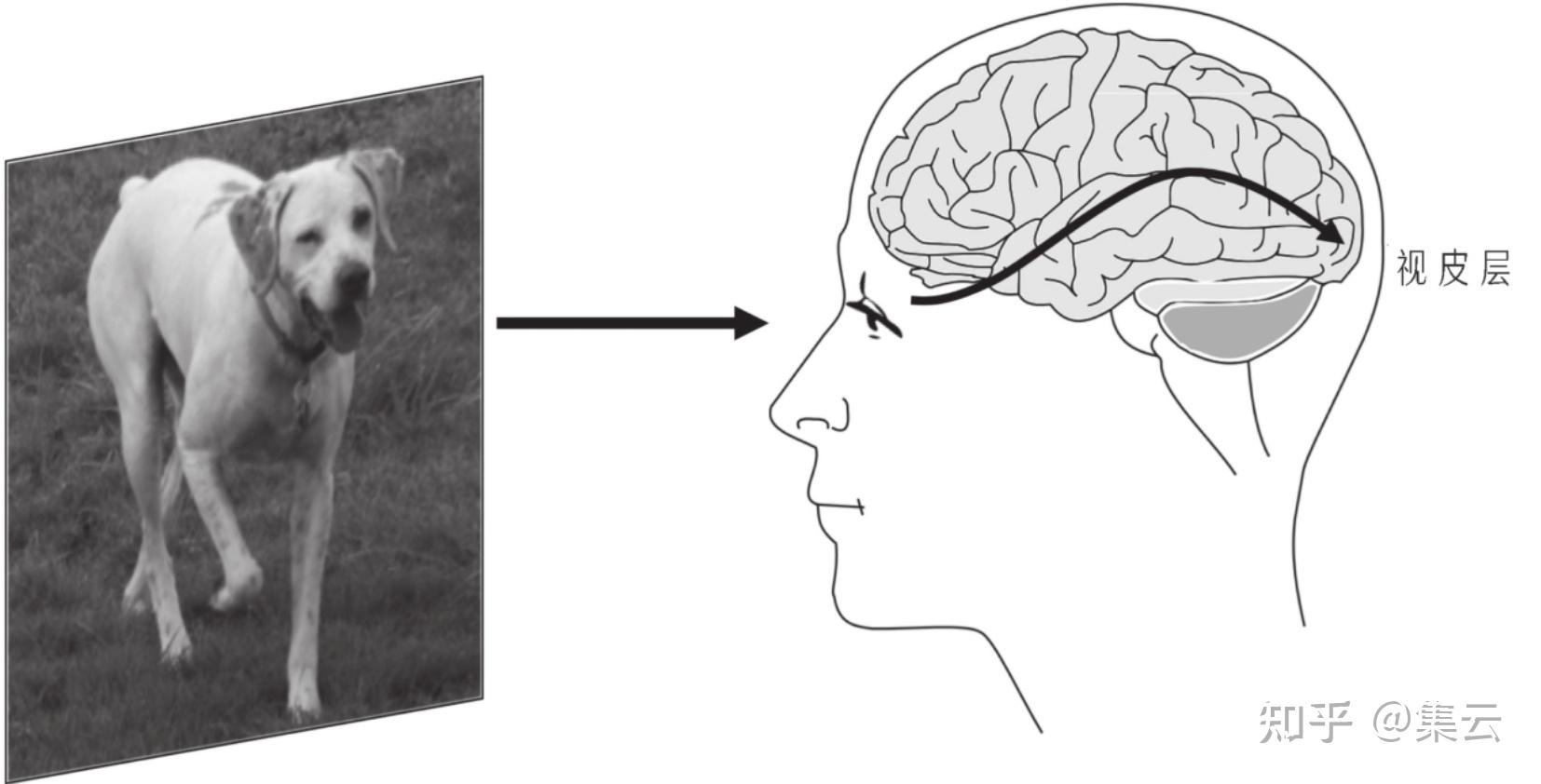
需要重点注意的是,视皮层中也会有自顶向下或反向的信息流,也就是信息从较高层向较低层传递,实际上,视皮层中反馈连接的数量约为前馈连接的10倍。尽管我们坚信我们的先验知识和预期应该是储存在更高层的大脑神经中的,并且会强烈地影响我们的感知,但神经科学家对这些反馈连接的作用仍然不甚了解。
类似于视皮层所做的:每个重要的视觉特征都有各自的神经映射。这些映射的组合就是唤起我们对场景产生感知的关键所在。
事实上,这些神经元对自己要响应哪一种边缘非常明确。
有些神经元,只有当其感受野中包含垂直边缘时,才会变得非常活跃;有些神经元只响应水平边缘;还有一些神经元则只对某些特定角度的边缘做出响应。胡贝尔和威塞尔最重要的发现之一是:人类视野中的每个小区域对应着许多不同的作为边缘检测器的神经元的感受野,也就是说,在视觉处理的低层次上,神经元在试着弄清楚场景中的每一组成部分的边缘方向,作为边缘检测器的神经元再将这一信息向视皮层的更高层进行传递。
虽然ConvNets使用反向传播算法从训练样本中获取参数(即权重),但这种学习是通过所谓的超参数(hyperparameters)集合来实现的,超参数是一个涵盖性术语,指的是网络的所有方面都需要由人类设定好以允许它开始,甚至“开始学习”这样的指令也需要人类设定好。超参数包括:网络中的层数、每层中单元感受野的大小、学习时每个权重变化的多少(被称为“学习率”),以及训练过程中的许多其他技术细节。设置一个ConvNets的过程被称为“调节超参数”,
调节的好坏对于ConvNets及其他机器学习系统能否良好运行是至关重要的。
正如微软研究院主任埃里克·霍维茨(Erik Horvitz)所说:“现在,我们所研究的不是一门科学,而是一种炼金术。”


5、监督学习
感知机在样本上进行这样的训练:在触发正确的行为时奖励,而在犯错时惩罚。如今,这种形式的条件计算在人工智能领域被称为监督学习(supervised learning)。
监督学习通常需要大量的正样本(例如,由不同的人书写的数字8的集合)和负样本(例如,其他手写的、不包括8的数字集合)。每个样本都由人来标记其类别——此处为“8”和“非8”两个类别,这些标记将被用作监督信号。
用于训练系统的正负样本,被称为“训练集”(training set),剩余的样本集合,也就是“测试集”(test set),用于评估系统在接受训练后的表现性能,以观察系统在一般情况下,而不仅仅是在训练样本上回答的正确率。


6、强化学习,最重要的是学会给机器人奖励
这种经典的训练技巧,在心理学上被称为操作性条件反射,已经在动物和人类身上应用了数个世纪。操作性条件反射使得一种重要的机器学习方法——强化学习得以出现。
在其最纯粹的形式下,强化学习不需要任何被标记的训练样本。代替它的是一个智能体,即学习程序,在一种特定环境(通常是计算机仿真环境)中执行一些动作,并偶尔从环境中获得奖励,这些间歇出现的奖励是智能体从学习中获得的唯一反馈。
与监督学习不同,强化学习可以使程序能够真正靠自己去学习,简单地通过在预设的环境中执行特定动作并观察其结果即可。
某些方面的人类指导对其成功至关重要,包括它的ConvNets的具体架构、对蒙特卡洛树搜索方法的使用,以及这两者所涉及的众多超参数的设置。


相关文章










Copyright©2023-2025 AIGC工具导航 津ICP备2022006237号-2 津公网安备12011002023007号 12377违法和不良信息举报中心 互联网违法和不良信息举报渠道
津公网安备12011002023007号 12377违法和不良信息举报中心 互联网违法和不良信息举报渠道